
在人工智能的浩瀚宇宙中,机器学习(Machine Learning)与深度学习(Deep Learning)如同两把不同的钥匙,各自解锁着通往智能世界的大门。今天,就让我们一起探讨这两者之间的区别,以及它们如何在不同场景下各显神通。
1.理论根基:从“经验归纳”到“分层抽象”
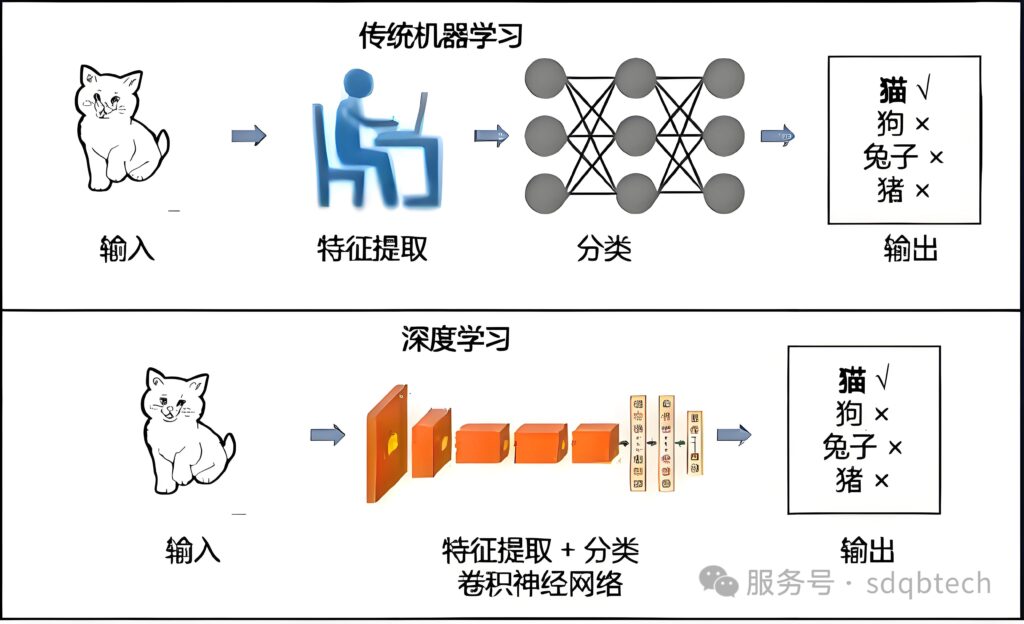
机器学习起源于统计学与概率论,它像是一位经验丰富的老工匠,通过数据构建数学模型,从大量的经验中提炼出规律。无论是经典的线性回归模型,还是复杂的支持向量机,它们的核心都在于通过显式定义的数学公式,描述数据的生成机制,并找到特征与标签之间的映射关系。这种方法的优势在于透明性,每个参数和决策步骤都有明确的数学解释。
而深度学习则更像是一位仿生学的探索者,它受到人脑神经网络结构与功能的启发,通过构建深层神经网络,自动学习数据的分层表示。这种“分层抽象”的能力,使得深度学习能够自动提取数据的复杂特征,无需人工设计特征提取器。例如,在图像识别中,卷积神经网络可以逐步提取图像的边缘、纹理、形状等特征,实现高精度的识别。
2.技术架构:从“显式编程”到“隐式表达”
传统机器学习算法通常具有明确的数学模型和编程逻辑,如决策树的递归划分、支持向量机的核函数映射等。这些模型的优势在于可解释性强,每个参数和决策步骤都可以追溯和解释。
相比之下,深度学习模型则更加复杂和抽象。它们由输入层、隐藏层和输出层构成,通过反向传播算法进行训练,依赖GPU/TPU加速矩阵运算。深度学习模型的参数规模巨大,如GPT-4的参数超过万亿,这使得它们能够处理更加复杂和高维的数据。然而,这种复杂性也带来了可解释性的挑战,深度学习模型的决策过程如同一个黑箱,难以直观理解。
3.实践应用:从“精准可控”到“泛化突破”
在实践应用中,机器学习与深度学习各有千秋。机器学习在金融风控、医疗诊断等领域表现出色,这些场景通常数据维度可控、因果关系明确,且模型的可解释性至关重要。而深度学习则在计算机视觉、自然语言处理等领域实现了颠覆性创新,展现了处理高维复杂数据的独特优势。例如,YOLO算法在实时目标检测中表现出色,BERT模型则颠覆了传统NLP任务的实现方式。
4.总结
总之,机器学习与深度学习是人工智能领域的两大支柱。它们各有优势,也各有挑战。随着技术的不断发展,我们有理由相信,这两把钥匙将共同开启更加智能、更加美好的未来。